大模型狂飙时代,各家发布会PPT越做越炫,但落到打工人手里,到底谁最“懂事”?参数再高、benchmark再漂亮,不如实战见真章。
“文科老板AI实战笔记”账号在四月第一周,对六款国产AI大模型进行了一场“脱去滤镜”的真实测评。不跑分、不背题,直接用14项贴近日常工作的真实对话任务进行打分。每次对话结束后,测试者根据回答质量独立打分。一周下来,累计完成了14项任务、多次追问,形成了完整的评分记录。
参与本次评测的六位选手分别是:阿里千问(通义千问)、KIMI(月之暗面)、腾讯元宝、DeepSeek(深度求索)、字节豆包、百度文心。
评测时间:2026年4月1日至4月6日
一、综合战力排行榜
综合战力榜:KIMI、豆包、元宝位列三甲
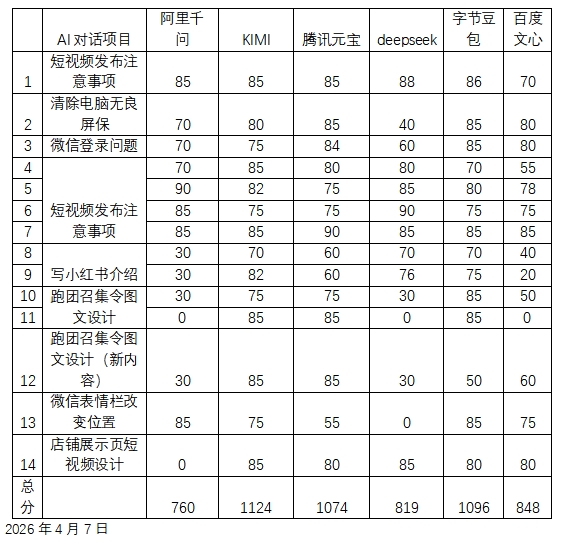
让我们先看总成绩。经过对所有任务得分(每项满分100分)的加总,六款AI的综合排名如下:
第一名:KIMI,总分1124分。
在长达一周、任务繁杂的测试中,KIMI表现出了惊人的稳定性。无论是创意构思还是操作指南,它都能给出结构清晰、实用性强的回答,极少出现“掉链子”的情况,堪称本次测试中的“全能型选手”。
第二名:字节豆包,总分1096分。
字节豆包以微弱的差距紧随其后。它在应对“网感”要求高的任务,如小红书文案、社群召集令时,表现尤其出色,语言风格活泼,能精准踩中目标用户的兴趣点,是本次测试的“创意与网感担当”。
第三名:腾讯元宝,总分1074分。
腾讯元宝同样实力不俗,稳居第一梯队。值得一提的是,在涉及微信生态、软件操作等具体问题上,元宝的回答往往更接地气,步骤详实,展现了其作为“生态内选手”的独特优势。
紧随其后的是百度文心一言(848分)、DeepSeek(819分)。
最后一句:阿里通义千问(760分)。各项都差。
二、任务分类深度解析
我们将14项任务分为几大类,逐一还原各模型的真实表现。
1. 深度思考、理解和商业策划
涉及任务:轻养型草本雄黄酒的愿景(多次追问)
得分情况:千问90分、85分、85分,KIMI82分、85分、75分,元宝75分、90分、75分,DeepSeek85分、75分、85分,豆包80分、85分、75分,文心78分、75分、85分
DeepSeek在需要深度逻辑和思考力上,能精准切中市场痛点,能力超越其他。千问得分也不错。
2. 创意内容与图文设计
涉及任务:写小红书介绍、跑团召集令图文设计(两次)
得分情况:
- 写小红书介绍(两次):KIMI70分、82分,DeepSeek70分、76分,豆包70分、75分,元宝60分、60分,文心40分、20分,千问30分、30分
- 跑团召集令图文设计(第一次):豆包85分,KIMI75分,元宝75分,文心50分,千问30分,DeepSeek30分
- 跑团召集令图文设计(第二次):KIMI85分,元宝85分,文心60分,豆包50分,千问30分,DeepSeek30分
豆包出图第一。这类任务考验模型的创意能力和指令遵循度。KIMI和豆包表现相对稳定,能够在格式限制、风格要求等约束下完成任务。千问和DeepSeek在此类任务上得分偏低,部分题目甚至得了0分。
3. 平台规则与运营指南
涉及任务:短视频发布注意事项(两次提问)
得分情况:
- 第一次:DeepSeek 88分,豆包 86分,千问、KIMI、元宝各85分,文心70分
- 第二次:KIMI 85分,元宝80分,DeepSeek 80分,千问70分,豆包70分,文心55分
这类问题考验模型对平台生态规则的抓取与归纳能力。DeepSeek和豆包能迅速提炼出“违规红线、流量推荐逻辑、发布黄金时间、标签策略”等实操要点,分点清晰且附带避坑建议。文心回答偏官方文档风格,术语较多,对新手运营不够友好。
4. 软硬件故障排查
涉及任务:清除电脑无良屏保、微信登录问题、微信表情栏改变位置
得分情况:
- 清除电脑无良屏保:元宝85分,豆包85分,文心80分,KIMI80分,千问70分,DeepSeek40分
- 微信登录问题:豆包85分,元宝84分,文心80分,KIMI75分,千问70分,DeepSeek60分
- 微信表情栏改变位置:千问85分,豆包85分,KIMI75分,文心75分,元宝55分,DeepSeek0分
故障排查极度依赖常识库与步骤拆解能力。元宝和豆包在多数故障类问题上表现稳定。DeepSeek在此类任务上遭遇明显困难。
5. 店铺展示页短视频设计
得分情况:KIMI85分,DeepSeek85分,元宝80分,豆包80分,文心80分,千问0分
多数模型在这一任务上表现尚可,KIMI和DeepSeek获得最高分。千问得了0分,说明在此类特定场景下存在明显短板。
三、总结与选型建议
AI不是替代者,而是放大器。选对工具、组合出击,才能让效率真正起飞。
数据来源:文科老板AI实战笔记
评测时间:2026年4月1日至4月6日
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
关键词: