内存不够只能割肉买DRAM?英特尔:很多时候大可不必。
人们常说,新一代的人工智能浪潮是由数据、算法和算力来驱动的。最近几年模型参数的爆炸式增长更是让大家看到了算力的基础性作用。
为了配合企业用户对于算力的强烈需求,当前的很多AI硬件(比如GPU)都铆足了劲儿地提高峰值算力,但这种提升通常以简化或者删除其他部分(例如内存的分层架构)为代价[1],这就造成 AI硬件的内存发展速度远远落后于算力的增长速度。
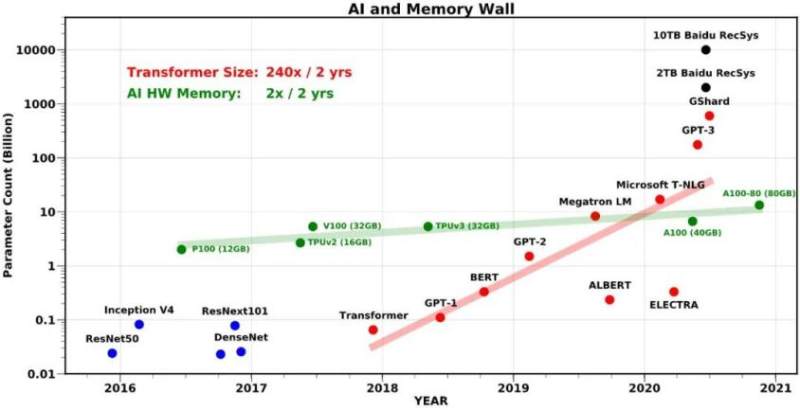
SOTA Transformer 模型参数量(红点)和AI硬件内存大小(绿点)增长趋势对比。图源:https://github.com/amirgholami/ai_and_memory_wall/blob/main/imgs/pdfs/model_size_scaling.pdf
因此,在遇到大模型的训练和推理时,用户总是感觉显存或内存不够用,这就是所谓的「内存墙」问题。
为了打破内存墙,人们想了很多种办法,比如前段时间大火的Colossal-AI项目就是一个适用于训练阶段的方法。在这个项目中,开发者高效利用了「GPU+CPU异构内存」的策略,使得一块消费级显卡就能训练180亿参数的大模型。
而在推理阶段,模型对硬件的主要需求就是加载模型的全部参数量,所以对算力要求相对低一些。一般对于计算密集型模型,我们可以采用INT8量化或者模型并行等策略,用多张GPU及其显存资源来推理单个模型。但实际上,还有很多工业界应用场景的机器学习或深度学习模型可以使用CPU与内存来做推理,例如推荐系统、点击预估等。
对于这些模型,我们除了内存容量上的诉求外,可能还需要考量异常情况下的数据恢复时间、硬件成本、维护成本等问题,这也对破解内存墙方案的选择提出了新的要求。
工业界的推理拦路虎:内存墙
在工业场景下,海量数据、高维模型确实能带来更好的效果,但这些数据的高维、稀疏特征又为计算和存储带来了很大的挑战。毕竟像推荐系统这样的模型,隐藏层大小可能就是数百万的量级,总参数量甚至能达到十万亿的量级,是GPT-3的百倍大小,所以其用户往往需要特别强大的内存支持系统才能实现更好的在线推理能力。
既然内存不够,那岂不是直接堆内存条(如DRAM)就够了?这从原理上是可行的,但一方面DRAM内存的价格不便宜啊,这类模型需要的内存又不是几百GB,而是动不动就冲上数十TB,而单条DRAM内存一般都只有几十GB,很少有超过128GB的。所以,整体算一下,不论是成本,还是在容量扩展上的能力,这一方案都不太容易被大家接受。
此外,DRAM内存还有一个问题,即数据是易失的,或者说:一断电就丢数据。有时候模型重启或者排除故障的时候,只能重新将权重从更慢的存储设备,如SSD或机械硬盘中加载到内存里,非常耽误时间,这对于在线推理业务来说是很难容忍的。
打破推理内存墙,不用DRAM用什么?
那么,除了添购DRAM这个不太划算的选择外,提供在线推理服务或使用这类应用的企业要打破内存墙,还有其他选择吗?
如果仔细比较一下不同存储层级的容量和延迟数据,我们可以发现,DRAM内存和固态盘 /硬盘存储之间其实存在很大的差距。如果能开发一种全新的存储部件或设备来填补这个缺口,那内存墙问题可能就会得到缓解。
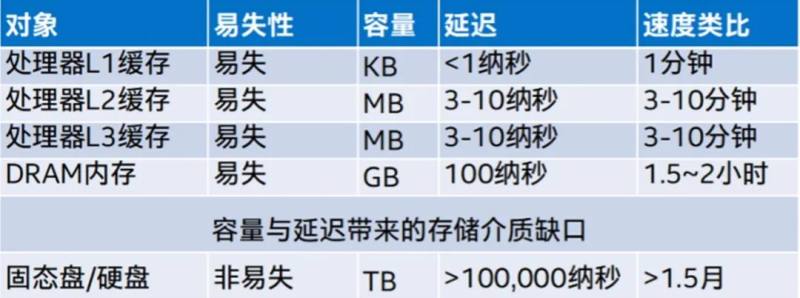
这就是英特尔®傲腾™ 持久内存(Intel® Optane™ Persistent Memory, 简称PMem)诞生的背景。其独有的傲腾™ 存储介质与先进的内存控制器和其它软硬件技术相结合,使其在性能上接近DRAM内存,在容量上又能有数倍的提升(单条容量可达512GB),用在基于第三代英特尔®至强®可扩展处理器的双路平台上时,理论上可提供最高达12TB的内存总容量(4TB DRAM+8TB 持久内存),相比之下,基于纯DRAM的方案不但在容量扩展能力上远远不及,在成本上也让人难以承受。
此外,傲腾™ 持久内存还有两个重要特性:可按字节寻址和数据持久性,分别汇集了内存与存储的优点。传统存储需要按块进行读写寻址,就如同去图书馆借书时,必须要把放置有目标书籍的整个书架上的书都背回家再做分拣,而内存按字节寻址则相当于能够精准定位目标书籍的位置并仅将其借出。

傲腾™ 持久内存在存储层级中的位置及作用
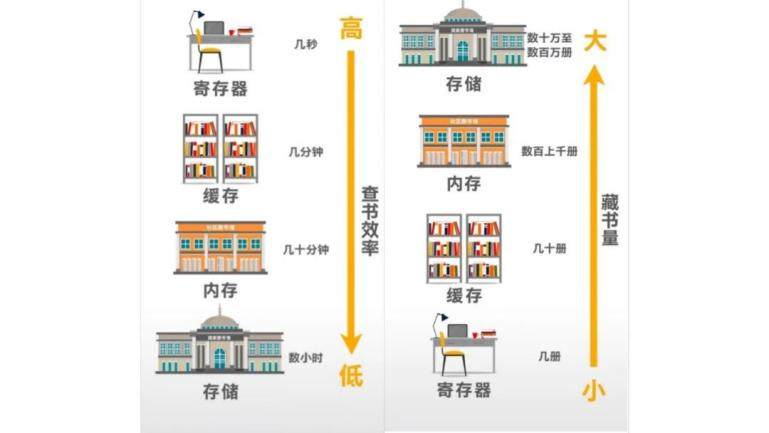

用书的存放和查找做例子,来理解不同存储层级的特点
数据持久性则补全了DRAM内存的先天不足,即可在断电后依然能保留数据,这就让大体量的内存数据库在计算系统出现计划内或计划外停机时,恢复数据及服务的速度大大加快,毕竟中间节省了从固态盘或硬盘上将数百GB,甚至是TB级数据读回内存的耗时。

PayPal的实践,证明持久内存很划算!
光练不说傻把式,光说不练假把式,傲腾™ 持久内存能不能帮助用户打破AI内存墙,我们还是要眼见为实。
以全球知名的在线支付服务商PayPal为例。和其他金融类服务企业一样,PayPal也难逃欺诈的挑战——即便在这方面的应对水平要高于业界的平均水平,每年损失仍会超过10亿美元。因此 PayPal对反欺诈格外上心,不但为此早早构建了具备强大反欺诈预防模型的实时决策系统,为了实时识别新出现的欺诈模式,PayPal还在不断强化这个系统在处理和分析相关数据时的效率。

对于本就承担着上百PB数据处理任务的 PayPal IT 基础设施来说,反欺诈决策平台数据量的增长和数据处理和分析效率的提升可是一个严峻的挑战。虽然它从2015年就导入了 Aerospike的数据库技术,将主索引数据存入内存来实现更好的实时性,但随着主索引数据规模的不断扩大,节点中的内存容量很容易耗尽,进而就会影响数据读写和处理的实时性。此时,若要采购新的节点又将耗费高昂的成本。注意,这里的成本不止包含硬件成本,还有随之而来的管理人员成本和功耗成本。
所以,PayPal更倾向于能够提高单位节点存储密度的方案。
综合这些诉求,PayPal选择了导入英特尔的傲腾™ 持久内存,而这里也有另一个先决条件,就是Aerospike正好是这款创新硬件发布后第一波支持它的数据库厂商之一。
借助Aerospike数据库的混合内存架构(HMA),PayPal可将主索引转存到傲腾™ 持久内存中,而非过去的DRAM中。这么做的好处非常明显,因为傲腾™ 持久内存的单条容量远高于DRAM,且每GB成本也显著低于 DRAM,这就可以帮助PayPal将每节点的总存储空间提高为原来的4倍(从 3.2 TB 到 12 TB),因此 PayPal只需使用更小的集群就可以满足业务所需的高性能,从而让服务器数量减少约50%,每集群的成本降低约30%。
将主索引存储在傲腾™ 持久内存中还有一个额外的好处,也就是我们前面提到的数据持久性。这使得Aerospike完成索引重建的时间从 59分钟缩短至 4分钟,满足了 PayPal对较长运行时间和更高可靠性的要求。据悉,英特尔和Aerospike之间多年的合作还成就了一系列更深层次的优化,包括在傲腾™ 持久内存中存储更多数据(不仅仅是索引)。
在采用傲腾™ 持久内存加持的Aerospike实时数据平台后,PayPal以其 2015年的欺诈数据量和此前使用的平台为基准做了一个评估,它发现新方案可以将其欺诈计算的服务级别协议(SLA)遵守率从 98.5%提升到99.95%,漏查的欺诈交易量降到约为原来的1/30。同时,与先前的基础设施相比,使用的服务器总数量可以减少近90%(从1024台减少到 120台),相关的硬件占用空间可减到约为原来的1/8,吞吐量可增至原来的5倍(每秒事务处理量从 20万提升到 100万),硬件成本下降为原来的约1/3( 预计硬件成本从 1250万美元省至 350万美元)。
需要指出的是,其实在PayPal的 IT基础设施中,傲腾™ 持久内存并不是一个孤立的部件,与它紧密配合且内置了AI加速能力(英特尔®深度学习加速技术)的第二代英特尔®至强®可扩展处理器也是这一解决方案的灵魂所在。相信如果把它换成AI加速能力以及内存子系统带宽和性能表现更优的第三代英特尔®至强®可扩展处理器,这种打破内存墙的效果将更加明显。
AlphaFold2端到端高通量优化
值得一提的是,在AI for Science 领域,至强® 可扩展处理器+傲腾™ 持久内存的组合所带来的突破内存墙实践也开始大放异彩。
以这几年大火的AlphaFold2为例。作为 AI for Science 领域的著名大模型,AlphaFold2的落地部署在算力和存储方面都面临着严峻的挑战,这也给内置高位宽优势(AVX-512等技术)的第三代英特尔®至强®可扩展处理器和大肚量的傲腾™ 持久内存提供了尽情发挥的空间。
据英特尔相关技术专家透露的信息,他们正在英特尔这套计算+存储的创新产品组合上优化AlphaFold2。一方面,在模型推理阶段,他们通过对注意力模块(attention unit)进行大张量切分(tensor slicing),以及使用英特尔® oneAPI 进行算子融合等优化方法,提升了算法的计算效率和CPU利用率,加快了并行推理速度,并缓解了算法执行中各个环节面临的内存瓶颈等问题。
另一方面,他们通过使用傲腾™ 持久内存,为AlphaFold 2 实现了 TB级内存的战略级支持,轻松解决了多实例并行执行时内存峰值叠加的内存瓶颈。这个瓶颈有多大?据英特尔专家介绍:在输入长度为765aa的条件下,64个实例并行执行时,内存容量的需求就会突破2TB。在这种情形下,对广大用户来说,使用傲腾™ 持久内存是一个可行且可负担的方案。
除了傲腾™ 持久内存,还有哪些方案可以打破内存墙?
虽然傲腾™ 持久内存的出现为一些应用场景提供了打破内存墙的可行路径,但截至目前,硬件领域还没有出现一个「一招鲜吃遍天」的内存墙解决方案,不过其他一些技术路径齐头并进的势头,还是让我们看到了解决这一问题的希望。讨论热度较高的解决方案包括在即将呈爆发式成长的异构系统中实现统一和池化的内存资源(把不同运算单元匹配的HBM、显存和系统内存集中管理和分配),以及前瞻性的存算一体架构等。
在异构系统中打造池化的内存资源是近年来针对算力和存储间瓶颈问题的比较热的一个创新方向。为了实现CPU与 GPU、FPGA等各种专用加速芯片的高速互联,英特尔早在2019年就牵头成立了名为CXL(Compute Express Link)的标准组织。对于存储来说,CXL将提供新的内存接口,与原来的DDR相比,它具有更高的可扩展性,更高的带宽,支持包括傲腾™ 产品在内的各种存储方案,而且它的架构设计不局限于单个系统,而是可以在多机之间进行连接,实现多机共享。大内存技术方案的代表性企业MemVerge的创始人兼 CEO范承工评价说,CXL是一个改变游戏规则的新技术,它可以实现内存和计算的相对独立,有望实现多机之间的内存池化共享以及真正的可组合基础设施,可以动态地为系统添加计算、内存、存储资源[2]。
存算一体则是让存储具备计算的能力,从而解决数据反复搬迁导致的效率低下问题。如今国内外众多企业都已经开展了存算一体技术的研发,包括英特尔、SK海力士、IBM、美光、三星、台积电、阿里等传统芯片大厂以及众多新兴AI和存储企业[3]。
不过,这些方案在成本、技术成熟度等方面还需要更多验证。
所以,尽管我们都希望看到更多前瞻性解决方案能够早日落地,但是短期来看,英特尔®傲腾™ 持久内存仍然是当前比较容易实现而且性价比较高的一种内存墙解决方案。况且,傲腾™ 持久内存的容量还在持续升级,不久之后就可能看到单条 1TB容量的产品出现,想必到了那时,其打破内存墙的效果将更加凸显。
参考链接:
[1]https://www.oneflow.org/a/share/jishuboke/75.html
[2]https://www.51cto.com/article/693956.html
[3]http://www.dzsb.net/index.php/2022/05/05/quanqiucunsuanyitijishuyanjiujiliangchanqingkuangzuixinjinzh/
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
关键词:









